Edge Video Analytics
Table of Contents
Objectives
Edge computing enables rapid video analytics by processing data closer to the source, thereby reducing end-to-end latency. This gives rise to the paradigm of edge video analytics (EVA). Object detection and object tracking are key building blocks of video analytics pipelines (VAPs), as their outputs directly impact the performance of downstream tasks. In real-world applications like traffic monitoring, timely and accurate responses are critical—delayed or inaccurate results can compromise safety. However, achieving such an accuracy-efficiency balance at the edge is particularly challenging due to two main factors: the compute-intensive nature of modern Convolutional Neural Network (CNN)- or Vision Transformer (ViT)-based models, and the limited computational and communication resources on edge devices. This project aims to improve the efficiency of object detection and tracking pipelines without sacrificing accuracy, enabling efficient and reliable EVA.
Participants
Research Thrusts
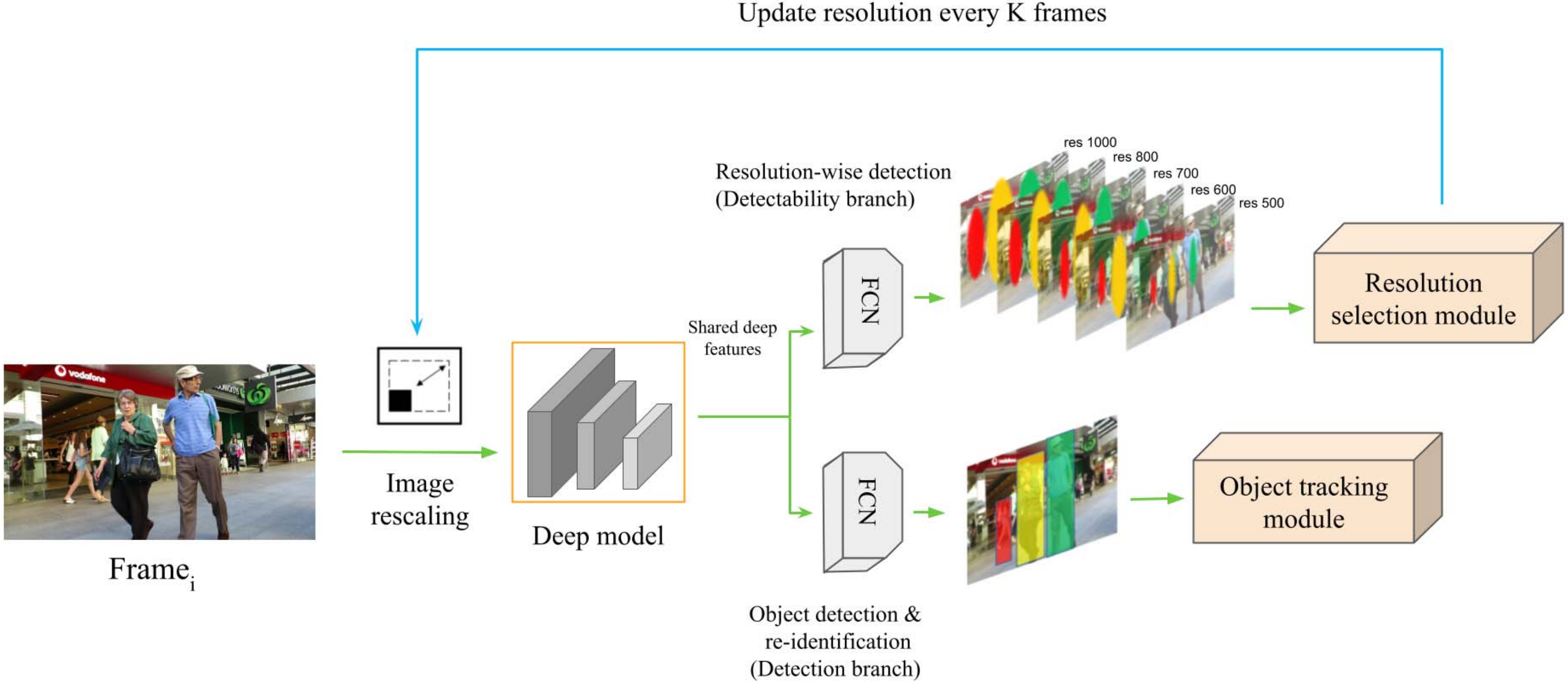
DeepScale: Online Frame Size Adaptation for Multi-object Tracking on Smart Cameras and Edge
In surveillance and search and rescue applications, it is important to perform multi-target tracking (MOT) in real-time on low-end devices. Today’s MOT solutions employ deep neural networks, which tend to have high computation complexity. Recognizing the effects of frame sizes on tracking performance, we propose DeepScale, a model agnostic frame size selection approach that operates on top of existing fully convolutional network-based trackers to accelerate tracking throughput. In the training stage, we incorporate detectability scores into a one-shot tracker architecture so that DeepScale can learn representation estimations for different frame sizes in a self-supervised manner. During inference, it can adapt frame sizes according to the complexity of visual contents based on user-controlled parameters. To leverage computation resources on edge servers, we propose two computation partition schemes tailored for MOT, namely, edge server only with adaptive frame-size transmission and edge server-assisted tracking. Extensive experiments and benchmark tests on MOT datasets demonstrate the effectiveness and flexibility of DeepScale. Compared to a state-of-the-art tracker, DeepScale++, a variant of DeepScale achieves 1.57X accelerated with only moderate degradation (∼2.3%) in tracking accuracy on the MOT15 dataset in one configuration. We have implemented and evaluated DeepScale++ and the proposed computation partition schemes on a small-scale testbed consisting of an NVIDIA Jetson TX2 board and a GPU server. The experiments reveal non-trivial trade-offs between tracking performance and latency compared to server-only or smart camera-only solutions.
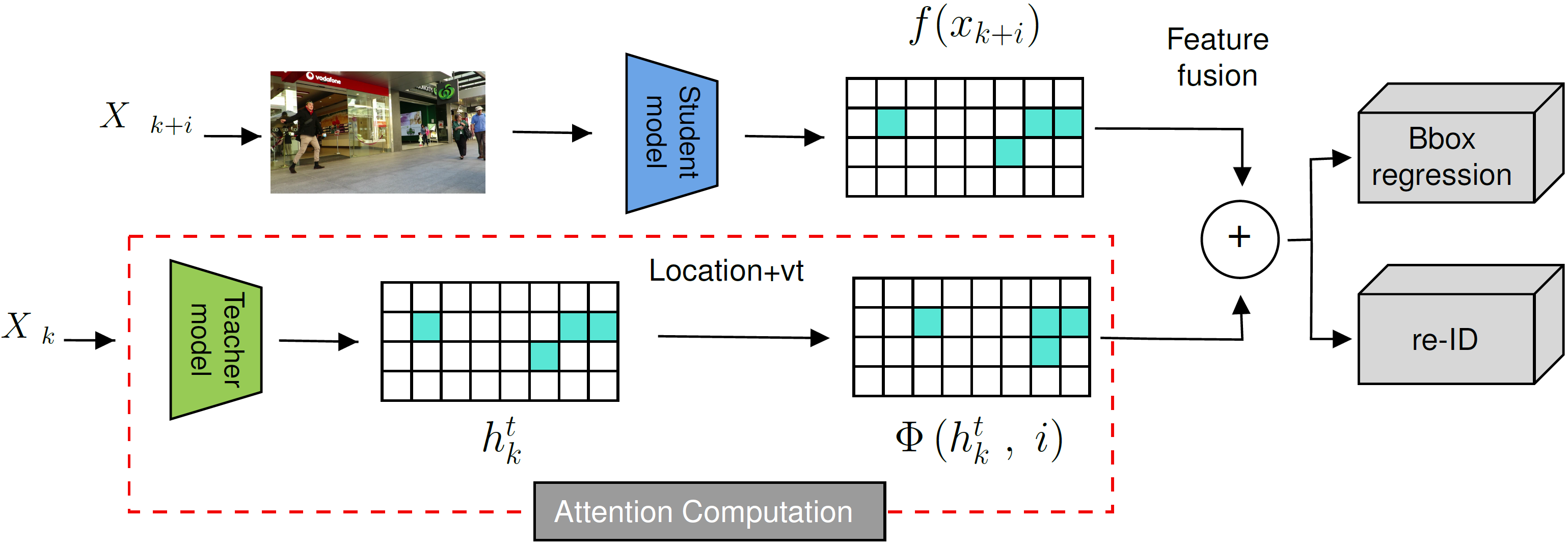
AttTrack: Online Deep Attention Transfer for Multi-object Tracking
Multi-object tracking (MOT) is a vital component of intelligent video analytics applications such as surveillance and autonomous driving. The time and storage complexity required to execute deep learning models for visual object tracking hinder their adoption on embedded devices with limited computing power. In this paper, we aim to accelerate MOT by transferring the knowledge from high-level features of a complex network (teacher) to a lightweight network (student) at both training and inference times. The proposed AttTrack framework has three key components: 1) cross-model feature learning to align intermediate representations from the teacher and student models, 2) interleaving the execution of the two models at inference time, and 3) incorporating the updated predictions from the teacher model as prior knowledge to assist the student model. Experiments on pedestrian tracking tasks are conducted on the MOT17 and MOT15 datasets using two different object detection backbones YOLOv5 and DLA34 show that AttTrack can significantly improve student model tracking performance while sacrificing only minor degradation of tracking speed.
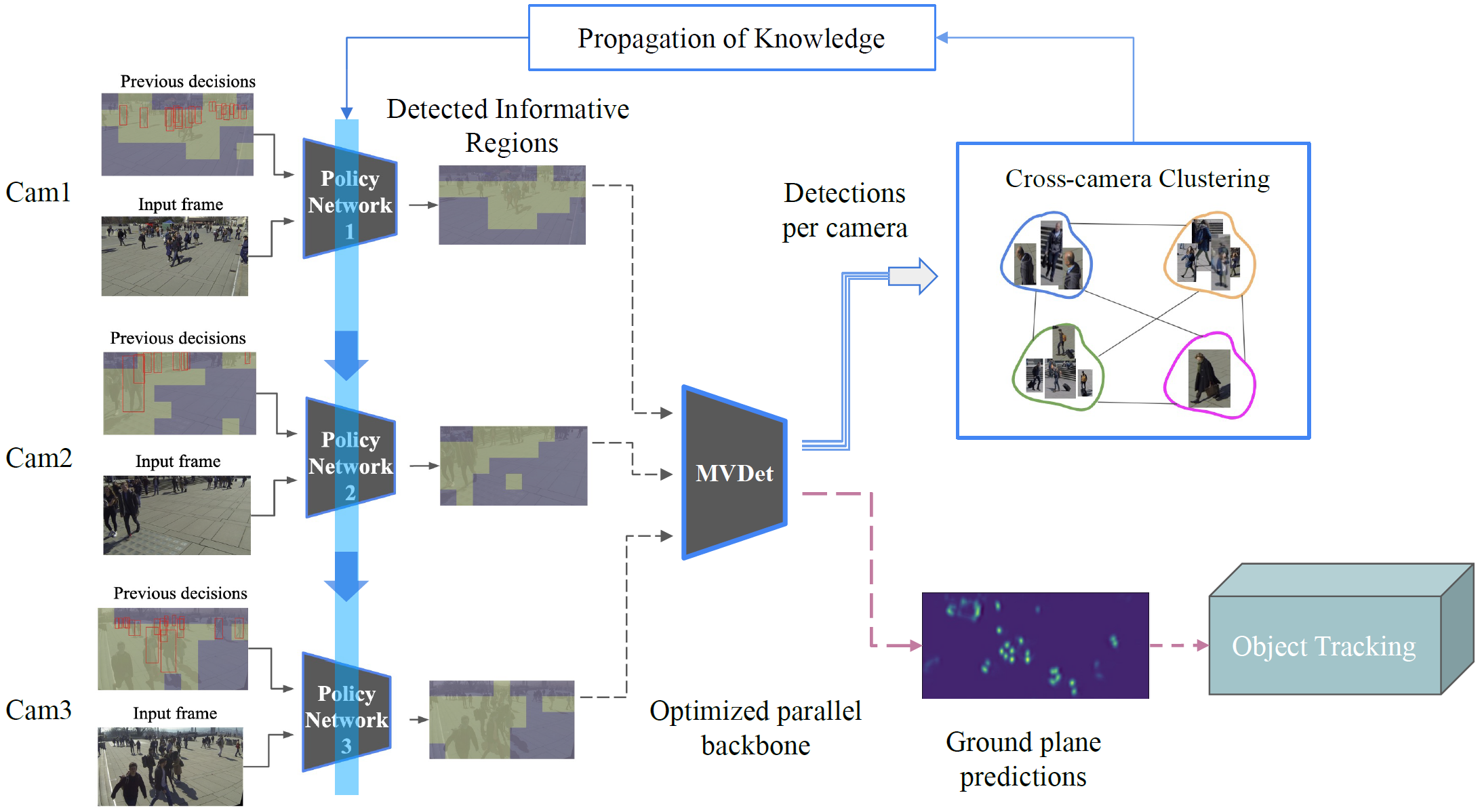
MVSparse: Distributed Cooperative Multi-camera Multi-target Tracking on the Edge
Tracking people in multi-camera surveillance systems is challenging due to disparate perspectives, large volumes of data, and high computation demands. This paper presents a distributed cooperative pipeline for pedestrian tracking that exploits the spatial and temporal redundancy within and across the video feeds from multiple synchronized cameras. It consists of three key components: 1) a lightweight policy network trained online in a self-supervised manner on each camera, 2) a sparse backbone processing unit purpose-built for parallel processing of selected regions of all cameras, and 3) an online clustering algorithm for object association. Utilizing online distributed reinforcement learning, the fully end-to-end trainable pipeline can accelerate any tracking-by-detection method by reducing detection costs across multiple perspectives. MVSparse has been evaluated using two multi-camera multi-target pedestrian tracking datasets, WildTrack and MultiviewX. It reduces the amount of processed regions by up to 52% and 39% with only moderate degradation of 1% and 0.1% in tracking accuracy on the two datasets, respectively. On a real-world testbed comprising four NVIDIA Jetson TX2 and a GPU server, MVSparse accelerates the end-to-end process and reduces the communication overheads by 1.88 and 1.60 X with only 2.27% and 3.17% degradation in tracking accuracy on the two datasets, respectively.
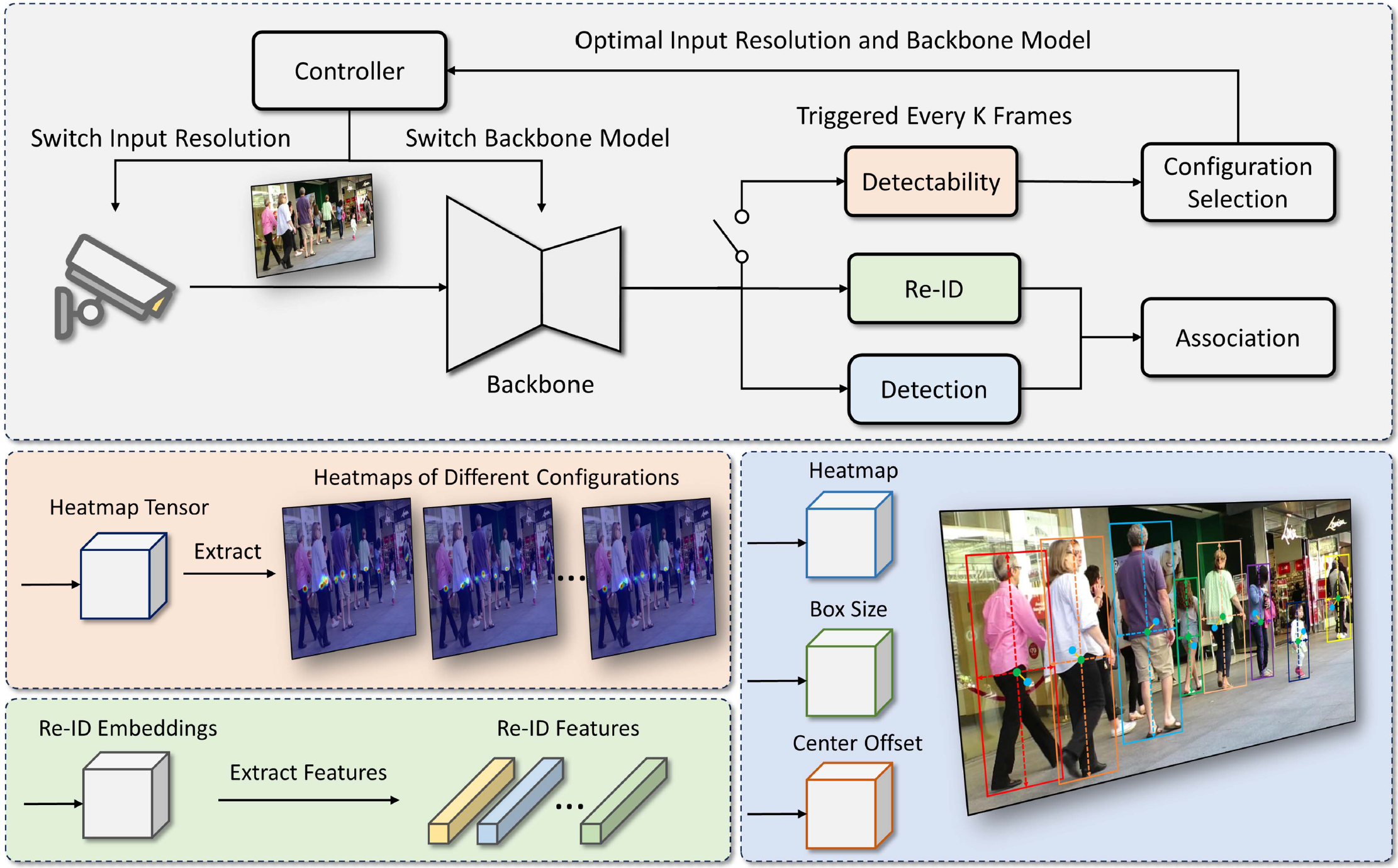
FastTuner: Fast Resolution and Model Tuning for Multi-Object Tracking in Edge Video Analytics
Multi-object tracking (MOT) is the “killer app” of edge video analytics. Deploying MOT pipelines for live video analytics poses a significant system challenge due to their computation-intensive nature. In this paper, we propose FastTuner, a model-agnostic framework that aims to accelerate MOT pipelines by adapting frame resolutions and backbone models. Unlike prior works that utilize a separate and time-consuming online profiling procedure to identify the optimal configuration, FastTuner incorporates multi-task learning to perform configuration selection and object tracking through a shared model. Multi-resolution training is employed to further improve the tracking accuracy across different resolutions. Furthermore, two workload placement schemes are designed for the practical deployment of FastTuner in edge video analytics systems. Extensive experiments demonstrate that FastTuner can achieve 1.1%–9.2% higher tracking accuracy and 2.5%–25.5% higher speed compared to the state-of-the-art methods, and accelerate end-to-end processing by 1.7%–22.5% in a real-world testbed consisting of an embedded device and an edge server.
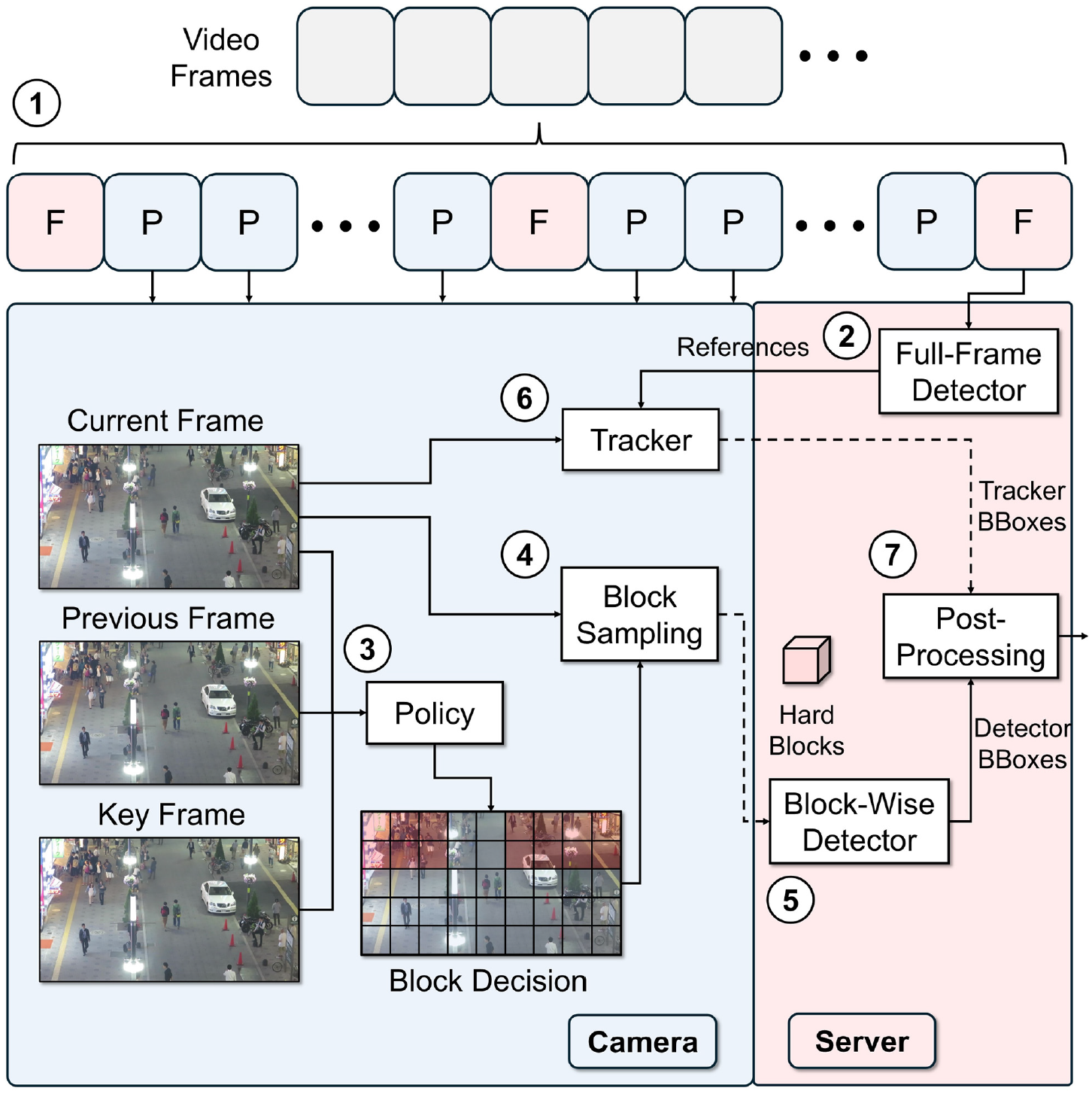
BlockHybrid: Accelerating Object Detection Pipelines With Hybrid Block-Wise Execution
Latency-sensitive edge video analytics applications require rapid responses for real-time decision-making, driving the demand for efficient object detection pipelines. Conventional pipelines transmit and process full frames, overlooking redundancy in videos and leading to unnecessary resource consumption. Existing block-wise conditional execution methods mitigate this issue by processing only informative blocks. However, they treat all informative blocks equally and fail to further categorize these blocks. To address this limitation, we propose BlockHybrid, an edge video analytics framework designed to accelerate object detection pipelines by hybrid block-wise execution. Specifically, BlockHybrid classifies blocks into hard or easy blocks using a policy network. Hard blocks are transmitted and processed by a block-wise detector on the server, while easy blocks are handled by an efficient tracker locally on the camera, reducing redundant computation and communication. Extensive experiments demonstrate that BlockHybrid can achieve 8.8%–31.5% higher local execution speed and comparable detection accuracy compared to state-of-the-art methods, and accelerate end-to-end processing—including camera-to-server communication—by 31.5%–39.1% in a real-world testbed.
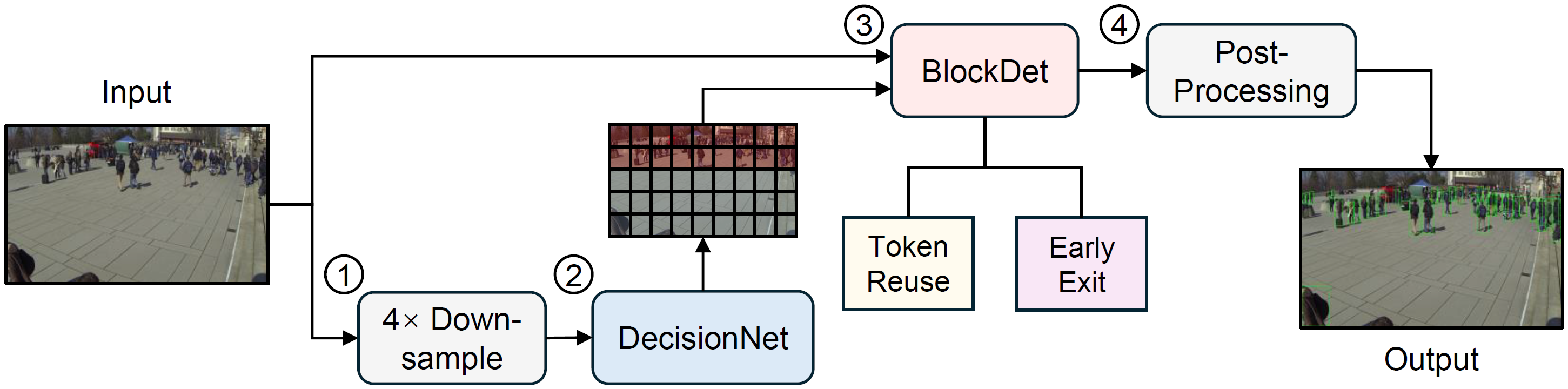
SEED: An End-to-End Selective Execution Framework for Transformer-Based Object Detection in Edge Video Analytics
We propose SEED, an End-to-End Selective execution framework for transformer-based object Detection. SEED accelerates vision transformer (ViT)-based detection pipelines in edge video analytics systems by allocating computation to informative blocks (IBs) while lightly processing non-IBs. It consists of a lightweight and decoupled decision network for real-time IB selection, and a block-wise ViT detector for selective inference. To demonstrate SEED's versatility, we implement two variants: SEED-TR, which reuses cached features for non-IBs, and SEED-EE, which terminates inference early for non-IBs. To enable optimal coordination between block selection and execution, we introduce a three-stage training strategy with pseudo-label supervision, allowing joint optimization of both networks. We evaluate SEED on two public benchmark datasets and a real-world edge video analytics testbed. Experimental results show that SEED-TR and SEED-EE accelerate execution by up to 75.5% and 57.4% on the benchmarks, and reduce end-to-end latency by up to 74.0% and 57.7% on the testbed, respectively, while maintaining detection accuracy comparable to full-frame inference.
Downloads
Acknowledgment
Publication
Nalaie Keivan, Xu Renjie, Zheng Rong. DeepScale: Online Frame Size Adaptation for Multi-object Tracking on Smart Cameras and Edge Servers, IEEE/ACM Seventh International Conference on Internet-of-Things Design and Implementation (IoTDI), pp. 67-79, 2022
Nalaie Keivan, Zheng Rong. AttTrack: Online Deep Attention Transfer for Multi-Object Tracking , In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pp. 1654-1663, 2023
Nalaie Keivan, Zheng Rong. Learning Online Policies for Person Tracking in Multi-View Environments , 2023
Nalaie Keivan, Zheng Rong. MVSparse: Distributed Cooperative Multi-camera Multi-target Tracking on the Edge IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), 2024
Nalaie Keivan, Xu Renjie, Zheng Rong. FastTuner: Fast Resolution and Model Tuning for Multi-Object Tracking in Edge Video Analytics, IEEE Transactions on Mobile Computing, 2025
Xu Renjie, Nalaie Keivan, Zheng Rong. BlockHybrid: Accelerating Object Detection Pipelines With Hybrid Block-Wise Execution, IEEE Internet of Things Journal, 2025